2020/4/30 更新
1. 多线程数据爬取
获取视频列表
获取视频列表的url为https://www.iqiyi.com/v_19ryi480ks.html。 即任意一期右侧的正片这一栏。
找到 li标签下 class为play-list-item的data-td属性
需要注意爬取后的列表第一个为预告,可以去掉,这里只爬取所有正片
获取评论列表
url参数:
content_id: 视频id 通过上方的的视频列表中获取
last_id: 上个最后的视频id,每次获取完成后,使用最后一个id,作为下次获取的last_id
page: 翻页的页数
page_size: 每页评论的个数
upremaining: 1最后一页, 0 后面还有内容
如何获取全部评论
两个思路
- 检查lastid 是否重复了,说明获取到最后一个
- 其实返回的data里有一个参数,"upremaining":0。检查这个为1就可以了。
参数里自带page,使用page=1,2,3,4实现翻页,最后一页remaining 参数为 1
page_size可以设大一点,减少请求次数。最大为40
因为评论数量过多,使用多进程爬取。每一个进程爬取一个视频下的评论,总共花了1分3秒。不用多线程的话,估计要20多分钟。
截至2020日4月29日总共爬取了254287条数据。
2. 数据清洗
发现很多评论里出现多次刷同一个选手名的现象。所以做一下选手名去重,这样能在预测选手成绩时能保证合理性,防止多计算出现次数。
如: 虞书欣虞书欣虞书欣虞书欣虞书欣冲呀!!!
清洗后为 虞书欣冲呀!!!
3. 分词
数据请求后, 评论列表不再改变可以转化为tuple使用, tuple的access速度会比list快
使用tuple分词用了 9分3秒,会比list快十几秒。
4. 选手词频统计
经过26万条评论统计,按前20选手姓名出现频率排序
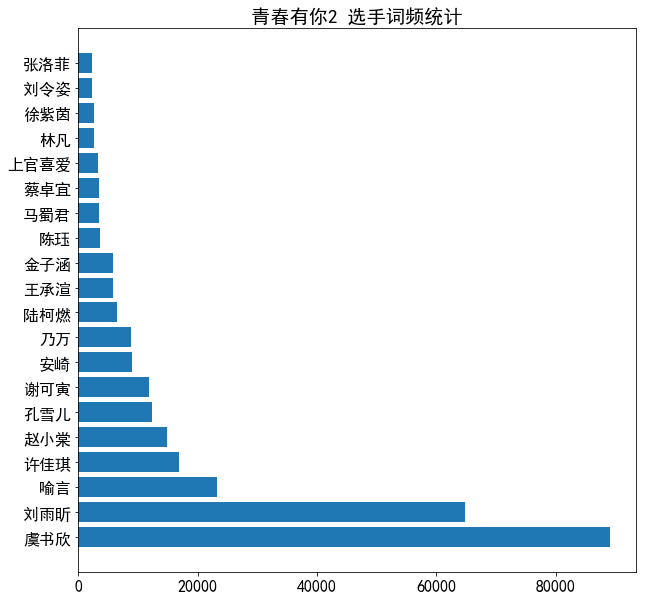
人名去重后,词频少了很多。

根据25号官方排名,前9名内除第9不一样,其他基本吻合。
5. 词云
按照词频显示词云

之前用形状和上色绘制了下词云,但是感觉效果没有原生的好。(这个是基于1000条数据生成的)

6. 节目评价
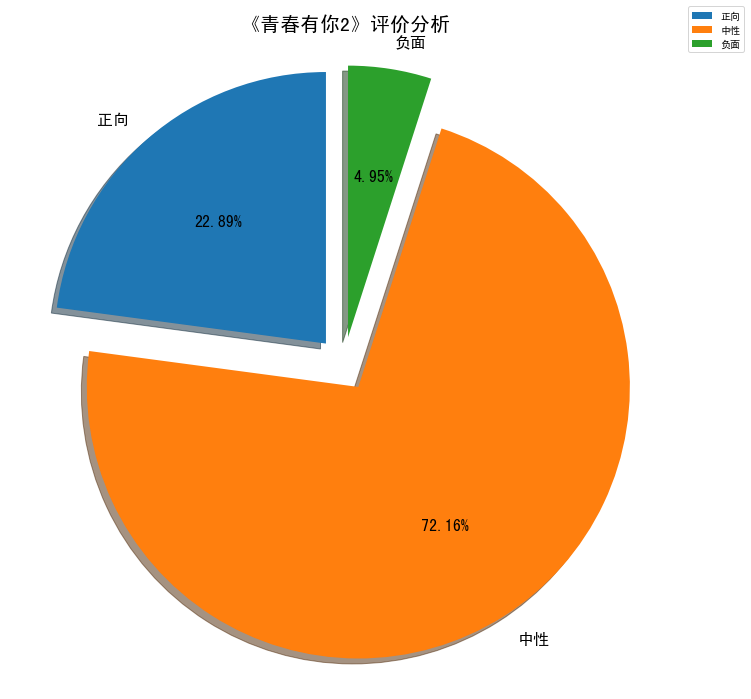
总体还是正向和中性评价占了绝大多数,95%。
随机打印一点 评价
正向:
['因为看了书欣的电视剧才来看这个的,喜欢她的性格', '我也喜欢左卓', '好喜欢刘雨昕!', '我真的太爱刘雨昕了', '好看好看', '看了这期,真的很心疼喻言', '安崎反差萌真的绝了,好看的颜值和有趣的灵魂她都拥有。', '我也喜欢虞书欣', '虞书欣加油', '冲着虞书欣搞笑视频来的,后面发现太太太多想pick的了。这种模式是看的第一个,努力又融洽的氛围真好。']
中性:
['乃万!', '乃万', '我要去看男团了拜拜,记得给我点赞', '大家要帮忙投票了吗我这儿还有13票', '大家有要帮忙投票的吗我还有14', '虞书欣', '乃万简直是可盐可甜可rap 可vocal, 随时写词的到处撩妹的博爱艺术家 。', '谢可寅小姐姐要加油喽。', '刘雨昕', '林凡']
负面;
['刘雨昕你咋不是个男的啊太帅了', '看得累死了磨磨叽叽', '我爱死所有训练生了', '傅如乔 爱死你了', '我就是看美女跳舞的,谁是谁,这个真不关心,长的都挺好看的,挺养眼', ''安琪的肚子真的不好看 感觉肚子肉好多 总喜欢露着腰,'入股不亏', '赵小棠什么鬼哦!', '真失望 为什么不是刘雨欣! 突然不想看了', '不要脸', '小蝴蝶胡馨尹很棒,呜呜呜不好意思之前没有发现你,不管在哪里都要继续加油呀!真的很棒!']
模型把很多人名识别成了中性词,对英文的词性识别可能还不是很好。
有一些负面评价识别还行,但是也有不准的时候。比如“爱死了”, "小蝴蝶胡馨尹很棒,呜呜呜不好意思之前没有发现你,不管在哪里都要继续加油呀!"可能把呜呜呜识别成负面了。
总结
跟原项目主要区别:多进程爬虫,多视频爬取,选手名去重,list改用tuple
经过爬取所有评论和同一句子人名去重后,发现数据可视化后还是变化挺大的。有很多人一个评论发很多重复的一个人名。
可拓展方面
评论生成,用文本生成模型生成一些青春有你相关的评论。
其实表情也是很好的反映观众心情的label, 也可以做这方面情感分析,finetuning 一下。根据评论生成表情,也会很有意思。
评论中还包括了大量的图片和动图,抓取下来,也可以做一些相应的拓展。
评论的用户信息分析,如地区
生成一个动态直方图,用户根据日期看不同日期的统计变化。参考视频,随便一个视频几万的播放量,我酸了